
In den letzten Jahren haben wir eine beispiellose Beschleunigung der KI-Entwicklung erlebt. Mit jedem neuen Modell, das veröffentlicht wird, scheinen wir der Vision einer Künstlichen Allgemeinen Intelligenz (AGI) näher zu kommen. Doch während die Leistungsfähigkeit dieser Systeme kontinuierlich steigt, wächst auch die Sorge um ihre Undurchsichtigkeit. Die grundlegende Frage lautet: Verstehen wir wirklich, was in unseren fortschrittlichsten KI-Modellen vor sich geht? Und werden wir dieses Verständnis bewahren können, wenn wir den Sprung zur Superintelligenz machen?
In seinem kürzlich veröffentlichten Essay "The Urgency of Interpretability" beschreibt Dario Amodei, CEO von Anthropic, die dringende Notwendigkeit, in die Interpretierbarkeit von KI-Systemen zu investieren. Gleichzeitig zeigt die Analyse von Situational Awareness, wie schnell wir von AGI zu Superintelligenz übergehen könnten – möglicherweise in weniger als einem Jahr durch automatisierte KI-Forschung, die menschliche Fortschritte um den Faktor 100 oder mehr beschleunigen könnte.
Diese Geschwindigkeit stellt uns vor ein Dilemma: Der wirtschaftliche und geopolitische Wettbewerb treibt eine rasante Entwicklung voran, während grundlegende Sicherheitsaspekte wie Interpretierbarkeit oft nachrangig behandelt werden. Müssen wir uns mit dieser Situation abfinden? Oder gibt es einen pragmatischen Weg vorwärts, der sowohl Fortschritt als auch Verständnis ermöglicht?
Warum ist Interpretierbarkeit wichtig?
Moderne KI-Systeme, insbesondere Large Language Models (LLMs), sind in ihrem Kern undurchsichtige "Black Boxes". Wenn Claude oder GPT eine Antwort generieren, verstehen selbst ihre Entwickler nicht vollständig, warum genau diese spezifische Ausgabe erzeugt wurde. Diese Undurchsichtigkeit ist kein Zufall – sie ist ein inhärentes Merkmal der Art und Weise, wie diese Systeme entstehen.
In some important way, we don't build neural networks. We grow them. We learn them. And so, understanding them becomes an exciting research problem.
Chris Olah, Research Lead for Interpretability bei Anthropic
Diese Analogie zu biologischen Lebensformen ist aufschlussreich. Wir setzen Bedingungen, die das Wachstum und die Entwicklung leiten – Daten, Architektur, Trainingsziele – aber die genaue Struktur, die daraus entsteht, ist komplex und schwer vorherzusagen. Wie ein Gärtner eine Pflanze kultiviert, ohne die genauen zellulären Prozesse zu verstehen, die ihr Wachstum steuern, "züchten" wir KI-Systeme, ohne ihre inneren Mechanismen vollständig zu durchschauen.
Die Risiken dieser Undurchsichtigkeit sind vielfältig:
- Alignment-Probleme: Ohne tiefes Verständnis ihrer Funktionsweise können wir nicht sicherstellen, dass KI-Systeme mit menschlichen Werten und Absichten übereinstimmen.
- Regulatorische Herausforderungen: In vielen Bereichen, wie dem Finanzsektor, verlangen Vorschriften explizit erklärbare Entscheidungsfindung.
- Fehlendes Vertrauen: Ohne Transparenz wird die gesellschaftliche Akzeptanz fortschrittlicher KI-Systeme gehemmt.
- Unentdeckte Schwachstellen: Sicherheitslücken und Fehlfunktionen können unentdeckt bleiben, wenn wir die inneren Mechanismen nicht verstehen.
Interpretierbarkeit im Kontext der Intelligence Explosion
Der Begriff "Intelligence Explosion" wurde bereits 1965 vom Mathematiker I.J. Good geprägt und beschreibt ein Szenario, in dem KI-Systeme ihre eigene Intelligenz verbessern, was zu einer sich selbst verstärkenden Spirale führt. Die aktuelle Forschung legt nahe, dass dieser Prozess nicht länger Science Fiction ist.
Die Analyse von Situational Awareness zeigt, wie dieser Prozess ablaufen könnte: Sobald wir AGI erreichen, könnten wir Millionen von automatisierten KI-Forschern einsetzen, die Tag und Nacht arbeiten und dabei 10x oder 100x schneller denken als Menschen. Diese könnten den algorithmischen Fortschritt, der normalerweise ein Jahrzehnt benötigt, auf ein Jahr oder weniger komprimieren.
In diesem Kontext wird Interpretierbarkeit zu einem entscheidenden Werkzeug, um die Risiken dieses schnellen Übergangs zu mindern:
- Sie könnte uns helfen, gefährliche Entwicklungen frühzeitig zu erkennen, bevor sie außer Kontrolle geraten.
- Sie ermöglicht uns, Sicherheitsgarantien zu etablieren, die auch bei zunehmender Modellkomplexität bestehen bleiben.
- Sie bietet eine Art "Rückverfolgbarkeit" der KI-Entwicklung, sodass wir verstehen können, wie und warum bestimmte Fähigkeiten entstehen.
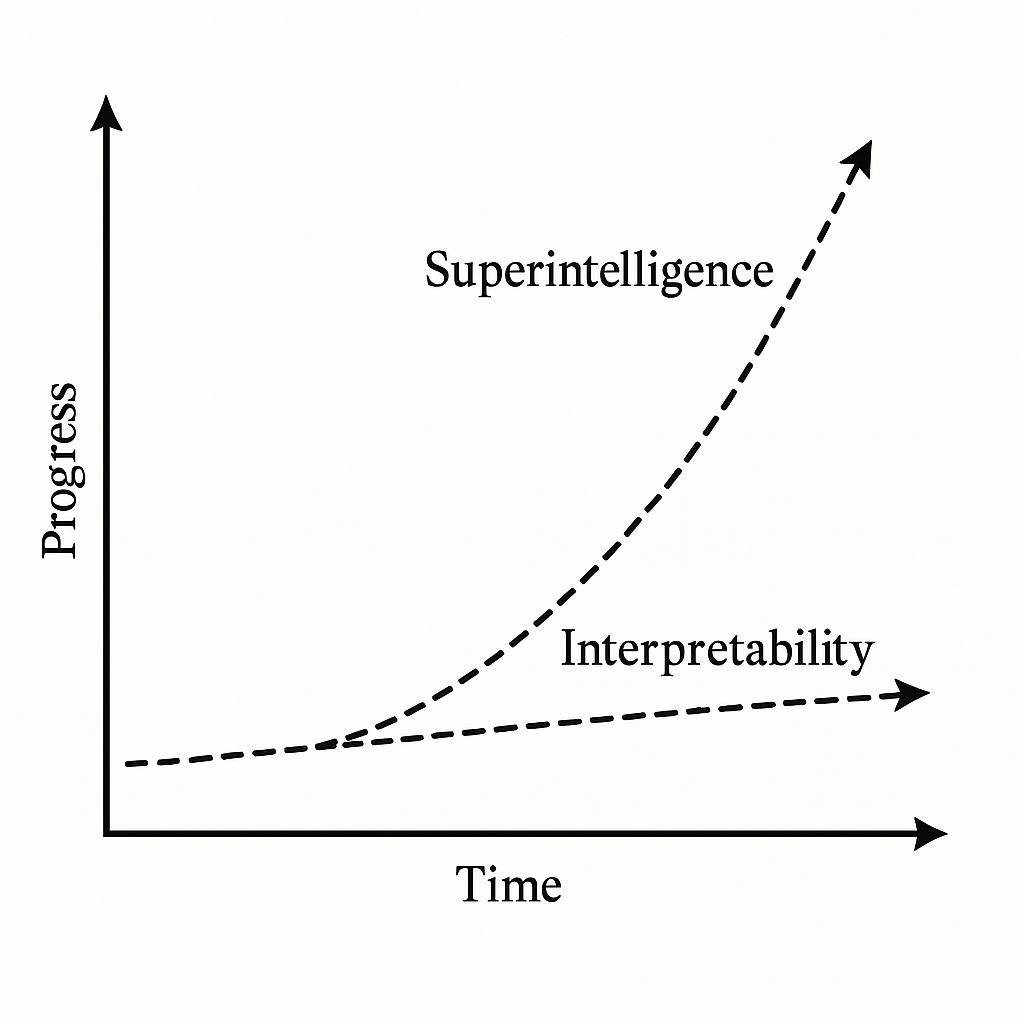
Allerdings befinden wir uns in einem Wettlauf zwischen der zunehmenden Komplexität von KI-Modellen und unserer Fähigkeit, sie zu interpretieren. Während Modelle wie Claude und GPT immer leistungsfähiger werden, kämpfen Forscher darum, Interpretationsmethoden zu entwickeln, die mit diesem Fortschritt Schritt halten können.
Der Finanz- und Immobiliensektor als pragmatische Anwendungsfälle
In stark regulierten Branchen wie dem Finanz- und Immobiliensektor ist Interpretierbarkeit nicht nur wünschenswert, sondern oft rechtlich erforderlich. Diese Sektoren bieten daher ideale Testfelder für interpretierbare KI-Ansätze.
Im Finanzsektor werden KI-Anwendungen bereits umfassend für Kreditbewertungen, Betrugserkennung, algorithmischen Handel und automatisierte Dokumentenverarbeitung eingesetzt. Etwa 70% der Finanzinstitute nutzen KI für Kreditrisikobewertungen und implementieren zunehmend erklärbare KI-Frameworks wie SHAP (SHapley Additive exPlanations), um Entscheidungen gegenüber Regulierungsbehörden und Kunden zu rechtfertigen.
Ein Beispiel für erfolgreiche Implementierung ist JP Morgan's Contract Intelligence (COiN), das maschinelles Lernen zur Analyse rechtlicher Dokumente einsetzt und etwa 150 relevante Attribute aus Geschäftskreditverträgen extrahiert. Das System verfügt über Erklärungsfunktionen, die den Nutzern helfen zu verstehen, warum bestimmte Klauseln markiert wurden – ein Ansatz, der sowohl das Vertrauen der Nutzer als auch die regulatorische Akzeptanz verbessert hat.
Im Immobiliensektor wird KI für automatisierte Immobilienbewertung, Portfoliooptimierung, Standortanalyse und vorausschauende Wartung eingesetzt. Diese Anwendungen erfordern Interpretierbarkeit, um Bewertungen gegenüber Kunden und Regulierungsbehörden zu rechtfertigen und strategische Investitionsentscheidungen zu unterstützen.
Interessanterweise zeigt die Forschung, dass der oft angenommene Trade-off zwischen Modellleistung und Interpretierbarkeit nicht immer zutreffen muss. Eine Studie in Business & Information Systems Engineering von 2024 verglich sieben generalisierte additive Modelle (GAMs), die von Natur aus interpretierbar sind, mit sieben gängigen Black-Box-Modellen für maschinelles Lernen und stellte fest, dass fortschrittliche GAMs eine vergleichbare Vorhersageleistung bieten können.
Praktische Ansätze zur Förderung von Interpretierbarkeit
Trotz der Herausforderungen gibt es vielversprechende technische und regulatorische Ansätze, um die Interpretierbarkeit von KI zu fördern:
Technische Lösungen
Die Forschung im Bereich der mechanistischen Interpretierbarkeit hat in den letzten Jahren bedeutende Fortschritte gemacht:
- Sparse Autoencoders und Dictionary Learning: Anthropic hat diese Techniken vorangetrieben, um interpretierbare "Features" in großen Sprachmodellen zu identifizieren. Im Mai 2024 veröffentlichte das Unternehmen "Scaling Monosemanticity" und enthüllte, dass sie 10 Millionen identifizierbare Features in Claude 3 Sonnet gefunden hatten.
- Circuit Tracing: Diese Methode ermöglicht es Forschern, spezifische Rechenwege in KI-Systemen zu kartieren und zu verstehen, wie das Modell Informationen verarbeitet und Entscheidungen trifft.
- Microsoft's Generalized Additive Models with Interactions (GA2Ms): Diese haben in Gesundheitsanwendungen gezeigt, dass sie State-of-the-Art-Genauigkeit erreichen können, während sie gleichzeitig interpretierbar bleiben.
Dokumentations- und Transparenz-Frameworks
Ergänzend zu technischen Lösungen haben Unternehmen standardisierte Dokumentationsframeworks entwickelt:
- Google's Model Cards: Diese begleiten trainierte ML-Modelle und detaillieren Leistungsmerkmale über verschiedene Bedingungen und demografische Gruppen hinweg.
- IBM's AI FactSheets: Sie bieten einen strukturierten Ansatz zur Dokumentation von Zweck, Leistung, Datensätzen und Trainingsmethoden von KI-Modellen, ähnlich wie Nährwertangaben für Lebensmittel.
Regulatorische Ansätze
Die regulatorische Landschaft entwickelt sich rasch, mit unterschiedlichen Ansätzen weltweit:
- EU AI Act: Die umfassendste Regulierung, die am 1. August 2024 in Kraft trat und stufenweise implementiert wird. Artikel 13 verlangt, dass Hochrisiko-KI-Systeme "ausreichend transparent" sein müssen.
- USA: Ein weniger restriktiver Ansatz, der sich auf freiwillige Selbstverpflichtungen der Industrie und sektorspezifische Regulierung konzentriert.
- China: Kombiniert strategische Regulierung mit Innovationsförderung, einschließlich obligatorischer Registrierung und Sicherheitsbewertung von KI-Modellen.
Allerdings weist die EU-Regulierung bedeutende Ausnahmen für militärische KI auf – ein Bereich, der aufgrund geopolitischer Spannungen und Wettbewerb besonders problematisch ist.
Wirtschaftliche Anreize
Entscheidend für die breitere Anwendung interpretierbarer KI sind wirtschaftliche Anreize:
- Regulatorische Compliance: Interpretierbare Modelle sind besser für DSGVO-Anforderungen positioniert und reduzieren Risiken in stark regulierten Branchen.
- Marktdifferenzierung: Transparente KI-Lösungen können Premium-Preise erzielen, besonders in Hochrisiko-Anwendungen.
- Betriebliche Effizienz: Interpretierbarkeit ermöglicht eine schnellere Identifikation und Korrektur von Fehlern sowie die Entdeckung wertvoller Domänenerkenntnisse.
Fazit: Ein pragmatischer Weg vorwärts
Die Forschung zeigt, dass wir bezüglich der Interpretierbarkeit im Streben nach Superintelligenz eine bedeutsame Wahl haben, obwohl diese Wahl erheblichen Einschränkungen unterliegt. Es gibt keine fundamentale technische Barriere, die Interpretierbarkeit mit fortschrittlichen KI-Fähigkeiten unvereinbar macht.
Allerdings stehen wir vor einem Rennen gegen die Zeit. Wie Dario Amodei es ausdrückt: "Wir befinden uns in einem Wettlauf zwischen Interpretierbarkeit und Modellintelligenz." Die wirtschaftlichen und geopolitischen Faktoren begünstigen eine schnelle Fähigkeitsentwicklung, während Sicherheitsaspekte oft nachrangig behandelt werden.
Ein pragmatischer Ansatz erkennt diese Realitäten an und sucht nach Wegen, Interpretierbarkeit als Wettbewerbsvorteil statt als Hindernis zu positionieren. Besonders in regulierten Branchen wie dem Finanzsektor können interpretierbare KI-Systeme einen deutlichen Mehrwert bieten – von verbesserter Compliance bis hin zu gesteigertem Kundenvertrauen.
Für Unternehmen und politische Entscheidungsträger empfehlen wir:
- Investitionen in interpretierbare KI-Forschung und -Entwicklung als strategische Priorität
- Integration von Interpretierbarkeit in den gesamten KI-Entwicklungszyklus, nicht als nachträgliche Überlegung
- Schaffung von Anreizen für interpretierbare KI durch gezielte Regulierung und Marktmechanismen
- Förderung internationaler Zusammenarbeit bei Interpretierbarkeitsstandards, auch wenn dies angesichts geopolitischer Spannungen herausfordernd ist
Während wir dem Zeitalter der Superintelligenz entgegengehen, wird die Fähigkeit, unsere eigenen Schöpfungen zu verstehen, nicht nur eine technische, sondern auch eine existenzielle Notwendigkeit. Die gute Nachricht ist: Wir haben die Werkzeuge und das Wissen, um diesen Weg zu gestalten – wenn wir den Willen aufbringen, dies zu tun.
Wie es Chris Olah treffend ausdrückt: "Wir züchten KI-Systeme mehr, als dass wir sie bauen." Es ist an der Zeit, dass wir nicht nur geschickte Züchter, sondern auch geduldige Naturforscher werden – die die innere Funktionsweise dieser neuen, gewachsenen Intelligenzen systematisch verstehen lernen.


